1. 背景
1.1. 大数据概念

1.2. 大数据管理系统
- 关系型
Oracle, DB2, MS SQL Server, Greenplum, TeraData, Vertica - 云平台
MapReduce, Apache Hadoop, MS Dryad - 云平台+SQL
Apache Hive, Yahoo Pig, MS Scope - No-SQL
Apache Hbase, Cassandra, MangoDB, Neo4j - 内存数据处理系统
MMDB, Spark, Cloudera impala - 图数据处理
Google Pregel, Apache Giraph, Graphlab
2. 关系型数据管理系统
2.1. 关系型数据模型
Table/Relation
- 列(Column)
- 行(Row)
通常是一个瘦长的表
2.1.1. 概念
2.1.1.1. Schema vs. Instance
Schema: 类型
一个表的类型是由每个列的类型决定的Instance: 具体取值
具体存储哪些记录,每个列的具体指
由具体用用决定
2.1.1.2. Key
- Primary key
- Foreign key
是另一个表的主键
2.2. 主要关系运算
- Selection(选择)
从一个表中提取一些行 - Projection(投影)
从一个表中提取一些列 - Join(连接)
- Equi-join(等值连接)
2.2.1. SQL Selcet

2.3. 数据库系统架构
通常的系统为典型的C/S结构:

- SQL Parser
- SQL语句的程序 -> 解析好的内部表达(例如:Parsing tree)
- 语法解析,语法检查,表名、列名、类型检查
- Query Optimizer
- SQL 内部表达 -> Query Plan(执行方案)
- 产生可行的query plan
- 估计query plan的运行时间和空间代价
- 在多个可行的query plans中选择最佳的query plan
- Data storage and indexing
- 如何在硬盘上存储数据
- 如何高效地访问硬盘上的数据
Buffer Pool:在内存中缓存硬盘的数据
Execution Engine
- query plan -> SQL语句的借故偶
- 根据query plan,完成相应的运算和操作
- 数据访问
- 关系型运算的实现
- Transaction management
- 目标是实现ACID
- 进行logging写日志,locking加锁
- 保证并行transactions事务的正确性
2.4. 数据存储与访问
2.4.1. 数据表(table)

数据在硬盘上的存储:
- 硬盘最小存储访问单位为一个山区: 512B
- 文件系统访问硬盘的单位通常为: 4KB
- RDBMS最小的存储单位是database page size
- Data page size可以设置为1~多个文件系统的page
- 例如, 4KB、8KB …

page内部结构:
- page header:存储page的一些信息,例如page ID
- slot:是一个定长整数数组,从后向前增长
- 记录:header和slot之间的空间,从前向后增长


数据的顺序访问:
1 | select Name, GPA |
- 顺序读取、student表的每个page
- 对于每个page,顺序访问每个tuple
- 检查条件是否成立
- 对于成立的读取Name和GPA
有什么性能问题吗?假如有100个系呢?
2.4.2. 索引(index)
Selective Data Access(有选择性的访问)
- 使用Index
- Tree based index:有序,支持点查询和范围查询
- Hash based index:无序,只支持点查询
- Clustered index(主索引)与Secondary index(二级索引)
- Clustered: 记录就存在index中,记录顺序就是index顺序
- Secondary: 记录顺序不是index顺序,index中存储page ID和in-page tuple slot ID.
- Chained Hash Table:
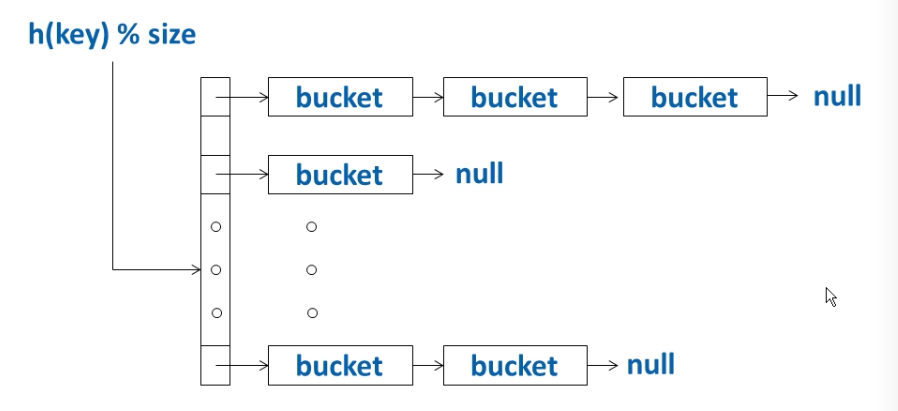

在硬盘上怎么存?
bucket = page
当chain上平均bucket数太多是,需要增大size,重新hashing。
- B+ Tree
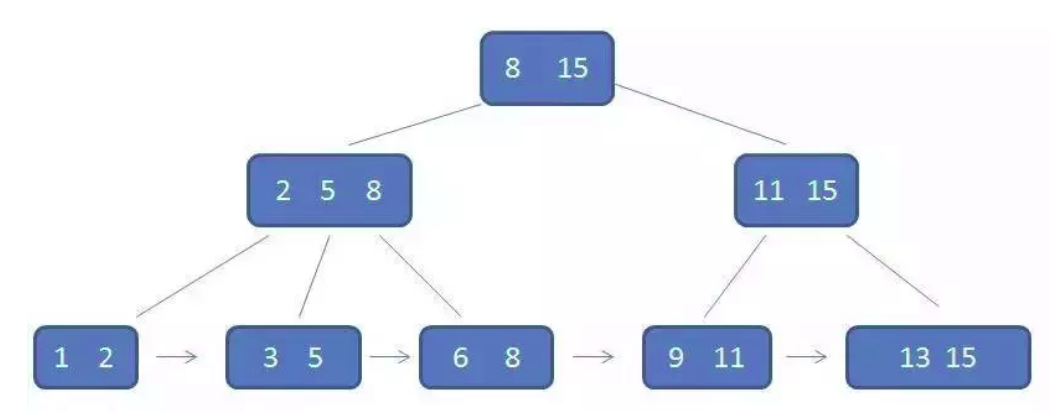

- 所有的叶子结点都位于同一层
- 每个叶子节点是一个page
- 所有key存储在叶子节点
- 内部节点完全是索引作用
叶子节点结构:
- Keys按照从小到达顺序排列: key1 < key2 < … < keyn
- 叶子节点从左向有也是从小到达顺序排列,以sibling pointer链起来(ptr = record ID; sibling = page ID)
Search代价:
- 共有N个key
- 每个节点的child/pointer个数为B
- 总I/O次数=树高 $O(log_B N)$
- 总比较次数
- 每个节点内部二分查找: $O(log_2 B)$
- $O(log_B N)*O(log_2 B) = O(log_2 N)$
删除操作:
- Search 人后在节点中删除
- node merge?
- 原设计:当节点中key个数小于一把
- 实际实现:数据总趋势是增长的,可以只有节点为空是才node merge或者完全不进行node merge
Range Scan:
- 找到其实叶节点,包括范围起始值
- 沿着叶的链接读下一个叶节点
- 直到遇到范围终止值

- 二级索引
假设已经建立了以Major为key的二级索引1
2
3select Name, GPA
from Student
where Major = '计算机'
- 在二级索引中搜索 Major = ‘计算机’
- 对于每个匹配项,访问相应的tuple
- 读取Name和GPA

2.4.3. 缓冲池(buffer pool)

数据访问的局部性:
Temporal locality(时间局部性)
- 同一个数据元素可能会在一段时间内多次被访问
- buffer pool
Spatial locality(空间局部性)
- 位置相近的数据元素可能会被一起访问
- Page 为单位读写
访问page的过程:
检查Page a是否在buffer pool中
是:buffer pool hit
- 直接访问buffer pool中的page a
否: buffer pool miss
- 在buffer pool中找到一个可用的frame
- 从硬盘读page a,放入这个frame
2.4.3.1 缓存替换算法
- LRU(Least Recently Used)
- Random
- FIFO
- Clock
数据库中使用Clock算法:
引用自
时钟置换算法可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。我们给每一个页面设置一个标记位u,u=1表示最近有使用u=0则表示该页面最近没有被使用,应该被逐出。
按照1-2-3-4的顺序访问页面,则缓冲池会以这样的一种顺序被填满:
此时如果要按照1-5的顺序访问,那么在访问1的时候是可以直接命中缓存返回的,但是访问5的时候,因为缓冲池已经满了,所以要进行一次逐出操作,其操作示意图如下:
每次遍历到一个节点发现u=1的,将该标记位置为0,然后遍历下一个页面,一轮遍历完后,发现没有可以被逐出的页面,则进行下一轮遍历,这次遍历之后发现原先1号页面的标记位u=0,则将该页面逐出,置换为页面5,并将指针指向下一个页面。
但是考虑一个问题,数据库里逐出的页面是要写回磁盘的,这是一个很昂贵的操作,因此我们应该优先考虑逐出那些没有被修改的页面,这样可以降低IO。
因此在时钟置换算法的基础上可以做一个改进,就是增加一个标记为m,修改过标记为1,没有修改过则标记为0。那么u和m组成了一个元组,有四种可能,其被逐出的优先顺序也不一样:
- (u=0, m=0) 没有使用也没有修改,被逐出的优先级最高;
- (u=1, m=0) 使用过,但是没有修改过,优先级第二;
- (u=0, m=1) 没有使用过,但是修改过,优先级第三;
- (u=1, m=1) 使用过也修改过,优先级第四。
1 | U为访问位,M为修改位。 |
2.5. 运算的实现
2.5.1. Operator tree

Query plan 最终将表现为一棵Operator Tree
- 每个节点代表一个运算
- 运算的输入来自孩子节点
- 运算的输出送往父亲节点
实现方法
- Operator at a time
- 完全处理一个运算在处理下一个运行,会产生大量中间结果
- Pull(Tuple at a time)
- 每个Operator实现Open, Close, GetNext方法
- 父节点调用子节点的GetNext() 取得下一个子节点的输出
- Push: 多线程
- 子节点吧输出放入中间结果缓冲,然后通知父节点去读
- Operator at a time
2.5.2. Selection & Projection
Selection: 行的过滤
- 支持多种数据类型:数值类型,字符串类型等
- 实现比较操作、数学运算、逻辑运算
Projection: 列的提取
- Query plan生成时,同时产生中间结果记录的schema
- 主要功能: 从一个记录中提取属性,生成一个结果记录
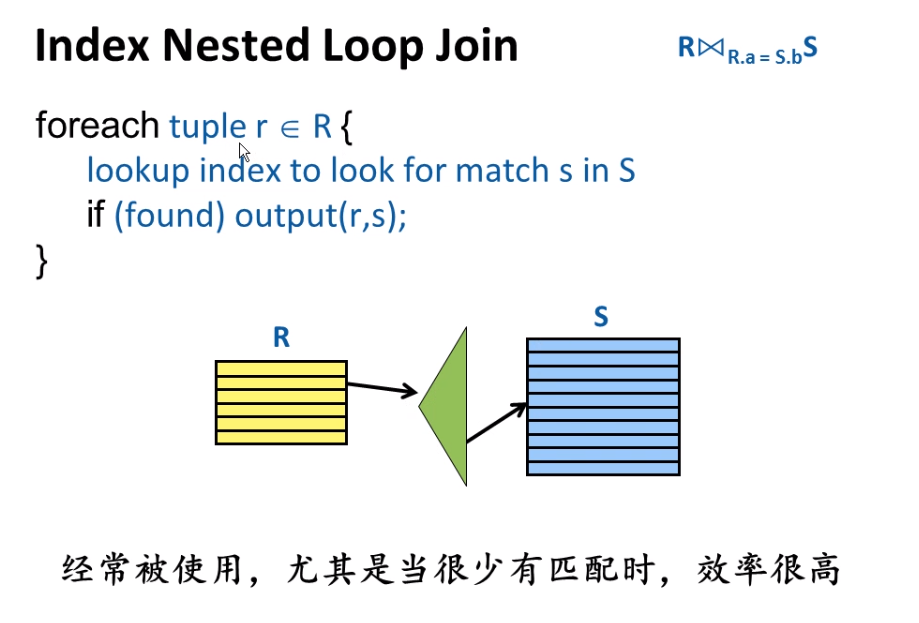
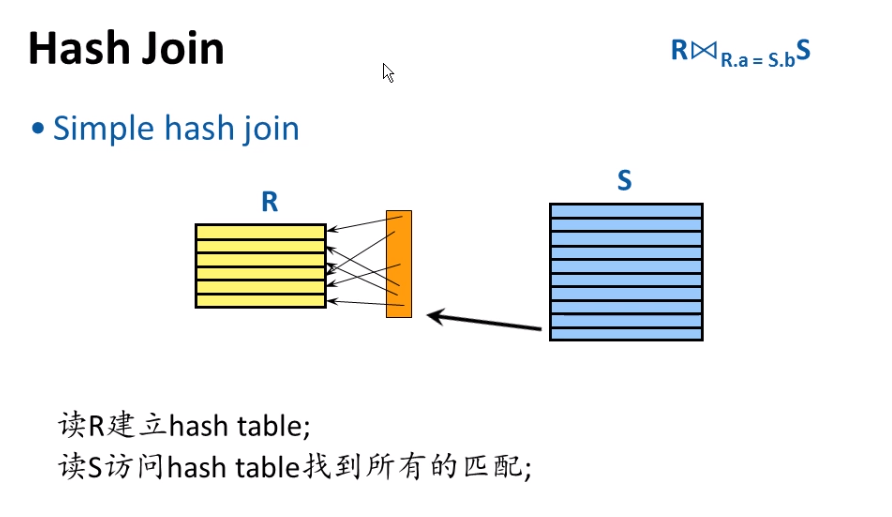
2.5.3. Join
实现思路:
- Nested loop
- Hashing
- Sorting
Nested loop
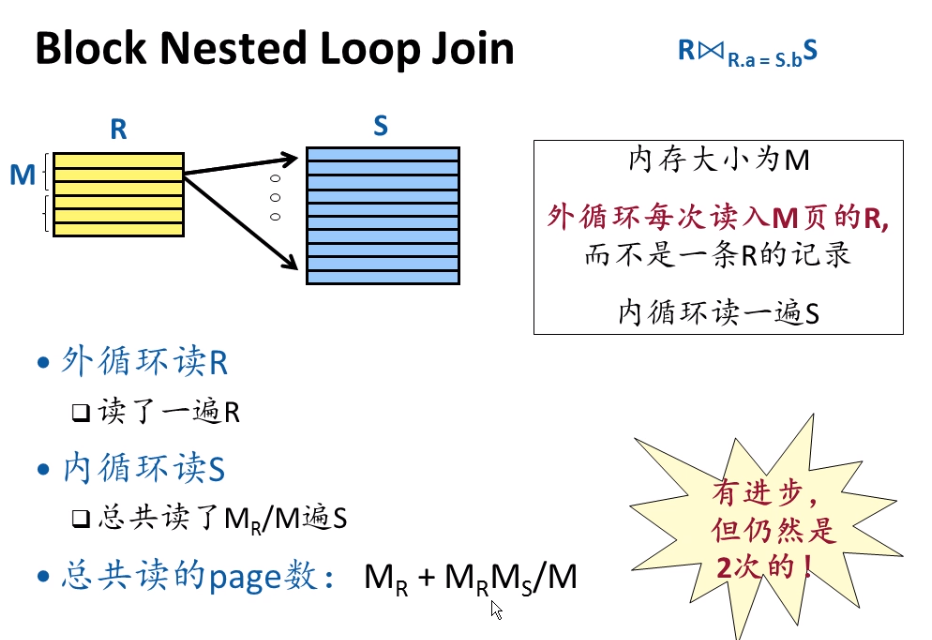
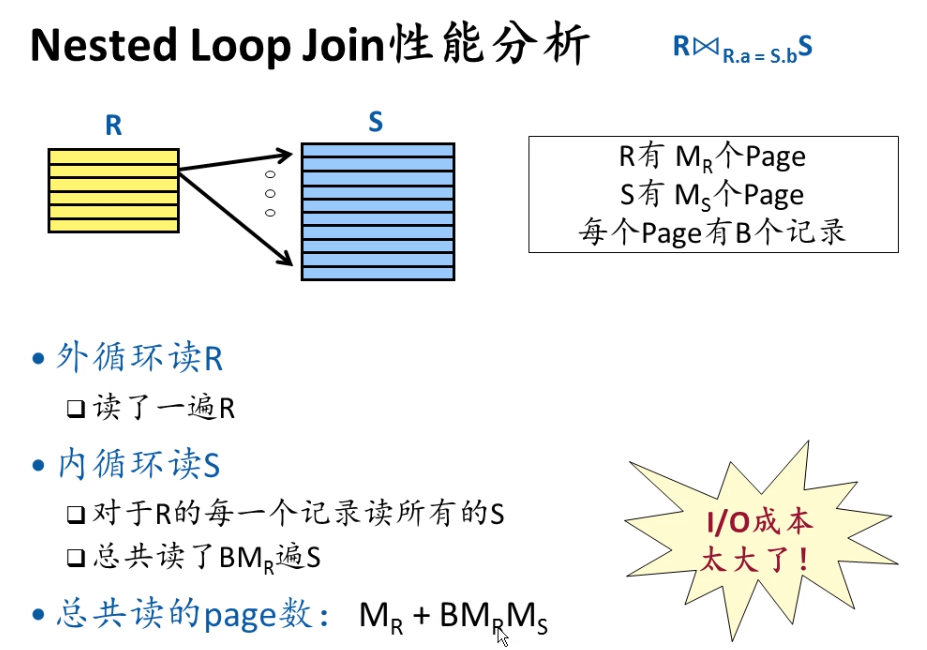
Hashing
如果遇到R比内存大应该怎么办?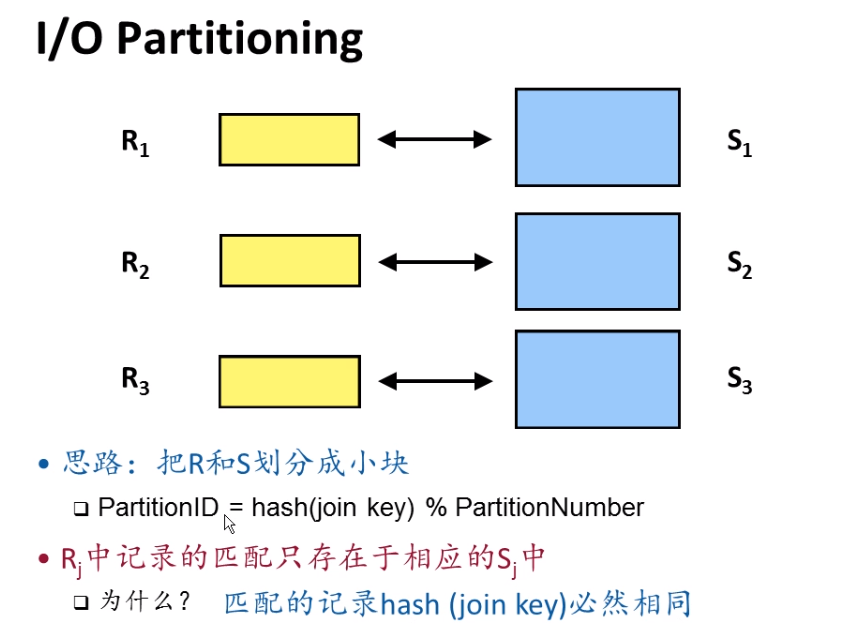





- GRACE Hash join

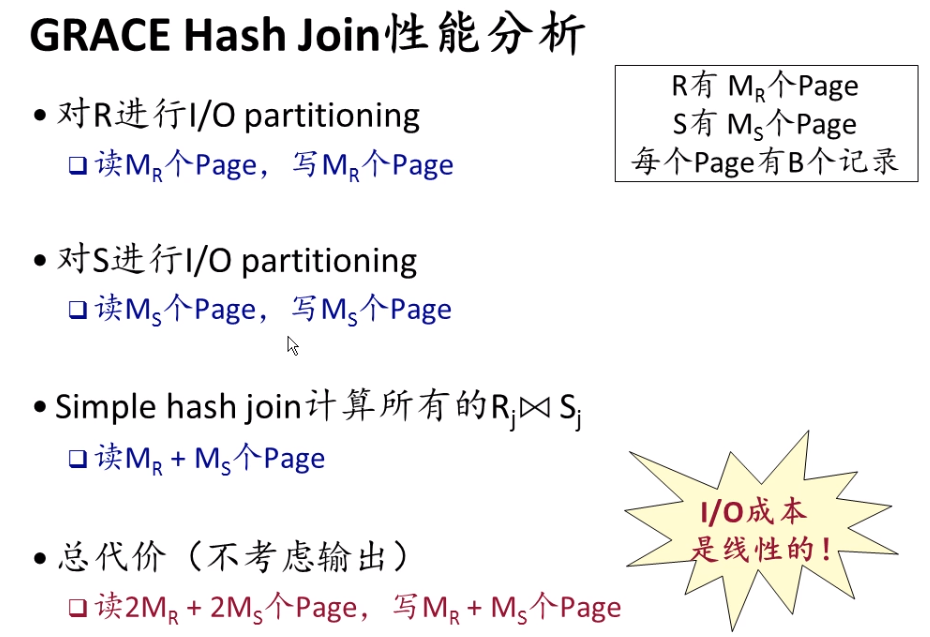


- sort merge join
- 思路:
- 如果把R按照R.a的顺序排序
- 如果把S按照S.b的顺序排序
- 那么可以Merge(归并)找出所有的匹配

- 比较:
- 通常代价比Hash Join稍差
- 当一个表已经有序的情况下,会被使用
2.6. Query Optimization(查询优化)

2.7. 事务处理(Transaction Processing)
大量并发用户,少量随机读写操作
- 一个事务可能包含多个操作
- select
- insert/delete/update
- 等
- 事务中的所有操作满足ACID性质
事务的表现形式:
- 没有特殊设置
那么每个SQL语句被认为是一个事务 - 使用特殊的语句
- 开始transaction
- 成功结束transaction
- 异常结束transaction
2.7.1. ACID
- Atomicity(原子性)
- all or nothing
- 要么完全执行,要么完全没有执行
- Consistency(一致性)
- 从一个正确状态转换到另一个正确状态(正确指:constraints, triggers等)
- Isolation(隔离性)
- 每个事务与其它并发事务互不影响
- Durability(持久性)
- Transaction commit后,结果持久有效,crash也不消失
2.7.2. Concurrency Control(并发控制后)
2.7.2.1. 数据冲突引起的问题:
- Read uncommitted data (读脏数据) (写读)
- 在T2 commit之前,T1读了T2已经修改了的数据
- Unrepeatable reads(不可重复读) (读写)
- 在T2 commit之前,T1写了T2已经读的数据
- 如果T2再次读同一个数据,那么将发现不同的值
- Overwrite uncommitted data (更新丢失) (写写)
- 在T2 commit之前,T1重写了T2已经修改了的数据
两大类解决方案:
Pessimistic (悲观)
- 假设:数据竞争可能经常出现
- 防止:采用某种机制保证数据竞争不会出现 – 如果一个Transaction T1可能和正在运行的其它Transaction有冲突,那么就让这个T1等待,一直等到有冲突的其它所有Transaction都完成为止,才开始执行。
Optimistic (乐观)
- 假设:数据竞争很少见
- 检查:先执行,在提交前检查是否没有数据竞争
- 允许所有Transaction都直接执行
- 但是Transaction不直接修改数据,而是把修改保留起来
- 当Transaction结束时,检查这些修改是否有数据竞争
- 没有竞争,成功结束,真正修改数据
- 有竞争,丢弃结果,重新计算
2.7.2.2. 悲观解决方案
Pessimistic: 加锁
- 使用加锁协议来实现
- 对于每个事务中的SQL语句,数据库系统自动检测其中的读、写的数据
- 对事务中的读写数据进行加锁
- 通常采用两阶段加锁(2 Phase Locking)
2 Phase Locking
- Pessimistic concurrency control
- 对每个访问的数据都要加锁后才能访问
- 算法如下
- 在Transaction开始时,对每个需要访问的数据加锁 – 如果不能加锁,就等待,直到加锁成功
- 执行Transaction的内容
- 在Transaction commit前,集中进行解锁
- Commit
- 有一个集中的加锁阶段和一个集中的解锁阶段
- 由此得名

实现细节2: Lock Granularity
- 锁的粒度是不同的
- Table?
- Record?
- Index?
- Leaf node?
- Intent locks
- IS(a):将对a下面更细粒度的数据元素进行读
- IX(a):将对a下面更细粒度的数据元素进行写
- 为了得到S,IS: 所有祖先必须为IS或IX
- 为了得到X,IX: 所有祖先必须为IX

实现细节3: deadlock
如何解决deadlock问题?
死锁避免
- 规定lock对象的顺序
- 按照顺序请求lock
- 适用于lock对象少的情况
数据库的lock对象很多,不适合死锁避免
死锁检测
- 周期地对长期等待的Transactions检查是否有circular wait
- 如果有,那么就选择环上其中一Transaction abort
2.7.2.3. 乐观的并发控制:不采用加锁
- 事务执行分为三个阶段
- 读:事务开始执行,读数据到私有工作区,并在私有工作区上完成事务的处理请求,完成修改操作
- 验证:如果事务决定提交,检查事务是否与其它事务冲突 – 如果存在冲突,那么终止事务,清空私有工作区 – 重试事务
- 写:验证通过,没有发现冲突,那么把私有工作区的修改
复制到数据库公共数据中
- 优点:当冲突很少时,没有加锁的开销
- 缺点:当冲突很多时,可能不断地重试,浪费大量资源,甚至无法前进
另一种并发控制方法:Snapshot Isolation
- 一种Optimistic concurrency control
- Snapshot: 一个时点的数据库数据状态
- Transaction
- 在起始时点的snapshot
- 读:这个snapshot的数据
- 写:先临时保存起来,在commit时检查有无冲突,有冲突就abort
- First writer wins


2.7.3. Crash Recovery(崩溃恢复)
2.7.3.1. Durability (持久性) 如何实现?
- Transaction commit后,结果持久有效,crash不消失
- 想法一
- 在transaction commit时,把所有的修改都写回硬盘
- 只有当写硬盘完成后,才commit
- 有什么问题?
- 正确性问题:如果写多个page,中间掉电,怎么办?
Atomicity被破坏了! - 性能问题:随机写硬盘,等待写完成
- 正确性问题:如果写多个page,中间掉电,怎么办?
解决方案:WAL (Write Ahead Logging)
- 什么是Logging
- 什么是Write-Ahead
- Logging 总是先于实际的操作
- Logging 相当于意向,先记录意向,然后再实际操作
- 怎样保证Durability
- 怎么实现Write-Ahead Logging
- Crash Recovery
Checkpoint:
- 为什么要用checkpoint?
- 为了使崩溃恢复的时间可控
- 如果没有checkpoint,可能需要读整个日志,redo/undo很多工作
- 定期执行checkpoint
- checkpoint的内容
- 当前活动的事务表:包括事务的最新日志的LSN
- 当前脏页表:每个页最早的尚未写回硬盘的LSN
2.7.3.2. 崩溃恢复
- 分析阶段
- 找到最后一个检查点
- 检查点的位置记录在硬盘上一个特定文件中
- 读这个文件,可以得知最后一个检查点的位置
- 找到日志崩溃点
- 如果是掉电等故障,必须找到日志的崩溃点
- 当日志是循环写时,需要从检查点扫描日志,检查每个日志页的校验码,发现校验码出错的位置,或者LSN变小的位置
- 确定崩溃时的活跃事务和脏页
- 最后一个检查点时的活跃事务表和脏页表
- 正向扫描日志,遇到commit, rollback, begin更新事务表 – 同时记录每个活动事务的最新LSN
- 遇到写更新脏页表 – 同时记录每个页的最早尚未写回硬盘的LSN
- Redo阶段
- 目标:把系统恢复到崩溃前瞬间的状态
- 找到所有脏页的最早的LSN
- 从这个LSN向日志尾正向读日志
- Redo每个日志修改记录
- 对于一个日志记录
- 如果其涉及的页不在脏页表中,那么跳过
- 如果数据页的LSN>=日志的LSN,那么跳过 – 数据页已经包含了这个修改
- 其它情况,修改数据页
- Undo阶段
- 目标:清除未提交的事务的修改
- 对于所有在崩溃时活跃的事务
- 找到这个事务最新的LSN
- 通过反向链表,读这个事务的所有日志记录
- undo所有未提交事务的修改
- Undo时,比较数据页的LSN和日志的LSN
- if (数据页LSN>=日志LSN) 时,才进行undo
2.8. 数据仓库
2.8.1. OLAP
2.8.2. 行式与列式数据库
列式存储:
- 数据仓库的分析查询
- 大部分情况只涉及一个表的少数几列
- 会读一大部分记录
- 在这种情况下,行式存储需要读很多无用的数据
- 采用列式存储可以降低读的数据量
列式存储的压缩
- 每个文件存储相同数据类型的值
- 数据更容易被压缩
- 比行式存储有更高的压缩比
列式存储的问题
- 如果用到了一个表的多个列
- 太多列拼装在一起,付出拼装代价很大
2.9. 分布式数据库
2.9.1. 系统架构
三种架构
- Shared memory
- 多芯片、多核
- 或Distributed shared memory
- Shared disk
- 多机连接相同的数据存储设备
- Shared nothing
- 普通意义上的机群系统
- 由以太网连接多台服务器
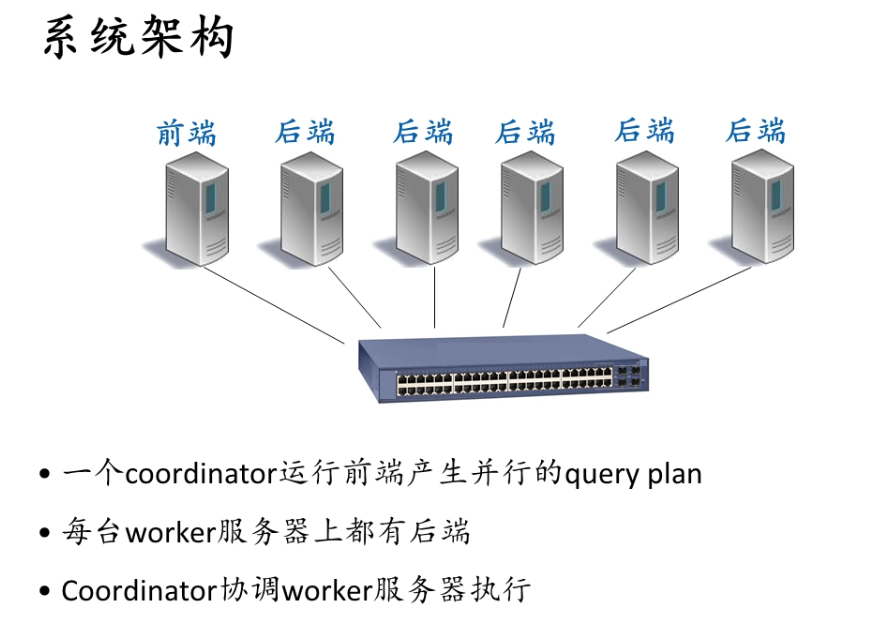

关键技术
Partitioning(划分)
- 把数据分布在多台服务器上
- 通常采用Horizontal partitioning – 把不同的记录分布在不同的服务器上
Replication(备份)
- 为了提高可靠性
- 对性能的影响
- 读?可能提高并行性
- 写?额外代价
Hash partitioning
- 类似GRACE: machine ID = hash(key) % MachineNumber
Range partitioning
- 每台服务器负责一个key的区间,所有区间都不重叠
2.9.2. 分布式查询处理
2.9.3. 分布式事务处理
2.9.3.1. 2 Phase Commit
- Participant: 完成分布式事务的部分读写操作
- Coordinator: 协调分布式事务的进行
- phase 1 (voting)
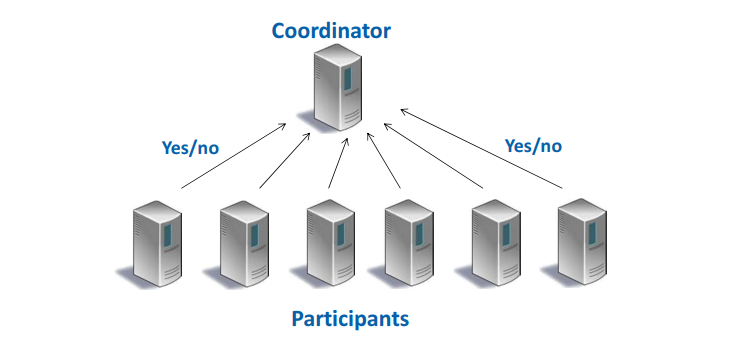

- Coordinator向每个participant发送query to commit消息
- 每个participant根据本地情况回答yes 或 no
- phase 2 (completion)
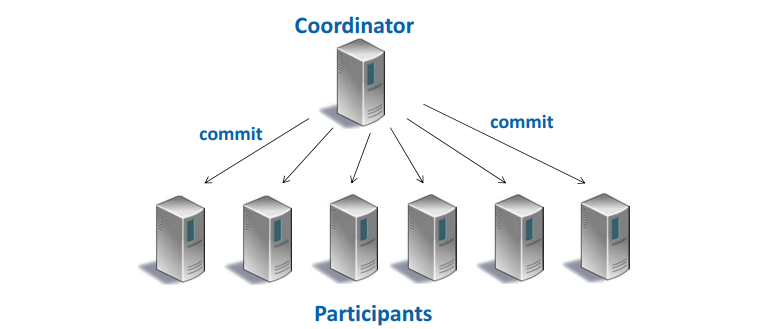

当所有的回答都是yes, transaction 将commit
Coordinator向每个participant发送commit消息
Participant 回答acknowledgment
当至少一个的回答是no, transaction 将abort
Coordinator向每个participant发送abort消息
Participant 回答acknowledgment
2.9.3.2. 崩溃恢复
- 恢复时日志中可能有下述情况
- 有commit或abort记录:那么分布式事务处理结果已经收到,进行相应的本地commit或abort
- 有prepare,而没有commit/abort:那么分布式事务的处理结果未知,需要和prepare记录中的coordinator进行联系
- 没有prepare/commit/abort:那么本地abort