1. 分布式系统基本概念
1.1. 网络与协议

1.1.1. IP/TCP/UDP
- IP (Internet Protocol)
- IPv4地址:例如210.76.211.7,唯一标识一台联网的机器
- Routing(路由)
- IP packet: header, data
- Connectionless (无连接), unordered(无序), best-effort (不保证可靠)
- TCP (Transmission Control Protocol)
- 在IP基础上实现
- Port端口号:不同的进程/socket
- Reliable (可靠的), ordered (有顺序), connection-oriented (有连接),error checked (数据校验)
- UDP (User Datagram Protocol)
- 在IP基础上实现
- Port端口号:不同的进程
- 进行数据校验,其它与IP相同
1.1.2. 应用层协议
- DNS
- HTTP
1.2. 通信方式
1.2.1. Process/Thread
- 在OS内核中两者很相似
- Process (进程)
- 创建:fork
- 私有的虚存空间
- 私有的打开文件 (files, sockets, devices, pipes …)
- Thread (线程)
- 创建:pthread_create -> clone
- 共享的虚存空间
- 共享的打开文件
- 一个进程中可以有多个线程
1.2.2. 应用程序进程间的通信方式
- Shared memory (共享内存)
- 在单机上
- 同一个进程内部,多个线程之间
- 多个进程之间,把同一块物理内存映射到多个进程的虚存空间中
- 一方修改,另一方可以立即看到
- 需要并发控制
- 在单机上
- Message passing (消息传递)
- 单机上,多进程之间
- 多机之间
- 例如:socket (TCP/UDP),pipe等
1.3. 分布式系统类型,故障类型,CAP
1.3.1. 分布式系统类型
- Client / Server
- 客户端发送请求,服务器完成操作,发回响应
- 例如:3-tier web architecture
- Presentation: web server
- Business Logic: application server
- Data: database server
- P2P (Peer-to-peer)
- 分布式系统中每个节点都执行相似的功能
- 整个系统功能完全是分布式完成的
- 没有中心控制节点
- Master / workers
- 有一个/一组节点为主,进行中心控制协调
- 其它多个节点为workers,完成具体工作
1.3.2. 故障模型(Failure Model)
- Fail stop
- 当出现故障时,进程停止/崩溃
- Fail slow
- 当出现故障时,运行速度变得很慢
- Byzantine failure
- 包含恶意攻击
1.3.3. CAP定理

2. 分布式文件系统
2.1. NFS (Sun’s Network File System)

2.1.1. Stateless(无状态)
- NFS Server不保持任何状态,每个操作都是无状态的
- NFSPROC_READ
- 输入参数: file handle, offset, count
- 返回结果: data, attributes
- NFSPROC_WRITE
- 输入参数: file handle, offset, count, data
- 返回结果: attributes
- NFSPROC_LOOKUP
- 输入参数: directory file handle, name of file/directory to look up
- 返回结果: file handle
- NFSPROC_GETATTR
- 输入参数: file handle
- 返回结果: attributes
- 等等
2.1.2 Idempotent(幂等性:重复多次结果不变)
- READ操作是Idempotent
- 在没有其它操作前提下,重复多次结果是一样的
- 为什么?
- WRITE操作是Idempotent
- 在没有其它操作前提下,重复多次结果是一样的
- 为什么?
2.1.3. Server Crash Recovery
- NFS Server
- 只用重启,什么额外操作都不用
- 因为Stateless
- NFS Client
- 如果一个请求没有响应,那么就不断重试
- 因为Idempotent
2.1.4. Cache Consistency
指对一个文件,并发访问冲突
NFSv2对于Cache Consistency的解决方法
- Flush-on-close (又称作close-to-open) consistency
-在文件关闭时,必须把缓存的已修改的文件数据,写回NFS Server - 每次在使用缓存的数据前,必须检查是否过时
- 用GETATTR请求去poll(轮询),获得最新的文件属性
- 比较文件修改时间
- 性能问题
- 大量的GETATTR(即使文件只被一个client缓存)
- 关闭文件的写回性能
2.2. AFS (Andrew File System)
- 设计目标:Scalability
- 一个服务器支持尽可能多的客户端
- 解决NFS polling状态的问题
2.2.1. 解决polling状态的问题
- Invalidation
- Client 获得一个文件时,在server上登记
- 当server发现文件修改时,向已登记的client发一个callback
- Client收到callback,则删除缓存的文件
2.3. 对比
其它不同点:AFS vs. NFSv2
- AFS缓存整个文件
- 而NFS是以数据页为单位的
- AFS open: 将把整个文件从Server读到Client
- 多次操作:就像本地文件一样
- 单次对一个大文件进行随机读/写:比较慢
- AFS缓存在本地硬盘中
- 而NFS的缓存是在内存中的
- 所以AFS可以缓存大文件
- AFS
- 有统一的名字空间,而NFS可以mount到任何地方
- 有详细权限管理等
3. Google File System 和 HDFS
3.1. GFS/HDFS
- Google File System
- SOSP 2003,C/C++实现
- Google MapReduce系统的基础
- Hadoop Distributed File System
- Google File System的开源实现
- 基于Java
- 应用层的文件系统
- 与Hadoop捆绑在一起
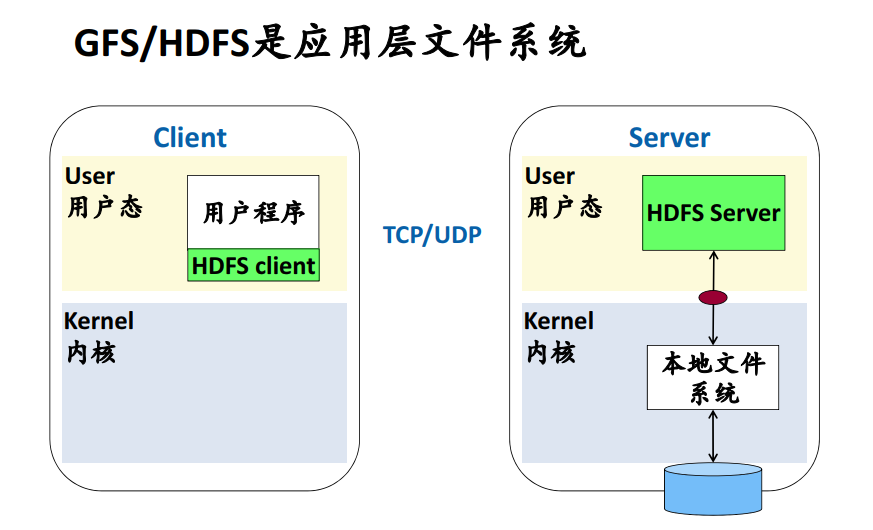

3.2. POSIX v.s. HDFS

3.3. 设计目标
- 优化
- 大块数据的顺序读
- 并行追加(append)
- 不支持
- 文件修改(overwrite)操作
- 所以,consistency的实现可以大大简化!
3.4. 系统架构

- Name Node:存储文件的metadata(元数据)
- 文件名,长度,分成多少数据块,每个数据块分布在哪些Data Node上
- Data Node: 存储数据块
- 文件切分成定长的数据块(默认为64MB大小的数据块)
- 每个数据块独立地分布存储在Data Node上
- 默认每个数据块存储3份,在3个不同的data node上
- Rack-aware
3.4.1. 文件操作: open
- 打开文件时,与Name Node通信一次
- 之后的读操作,直接与Data Node通信,绕过了Name Node
- 可以从多个副本中选择最佳的Data Node读取数据
- 可以支持很多并发的读请求
3.4.2. 文件操作: write

- Name Node决定应该写到哪些Data Nodes
- Rack-aware, load balancing
- 3个副本:本机、本机柜、其它机柜

- 形成一个数据传递的pipeline
- 数据依次沿流水线传递到Primary和secondary data node
- 最大限度地利用网络带宽
- Data node 在内存中缓存数据
- 注意:数据到此时还没有写进HDFS

- 收到写命令时才进行真正地写操作
- 把缓存的数据写到文件系统中
不允许并发写操作,因为可能造成块覆盖的问题,如下图:
支持并发apend操作,如下图:
3.5. 小结
- 分布式文件系统
- 很好的顺序读性能
- 为大块数据的顺序读优化
- 不支持并行的写操作:不需要distributed transaction
- 支持并行的append
4. Key-Value Store
- Dynamo
- Bigtable/ Hbase
- Cassandra
- RocksDB